 |
 |
|
|
|
|
ПОЛИТОЛОГИЯ: МЕТОДЫ ИССЛЕДОВАНИЯ |
|
|
|
|
|
|
|
|
ПОЛИТОЛОГИЯ: МЕТОДЫ ИССЛЕДОВАНИЯ |
|
НАЗАД Мангейм Дж., Рич Р.К. Политология. Методы исследования ВПЕРЕД
Красным шрифтом в квадратных скобках обозначается конец текста на соответствующей странице печатного оригинала данного издания
15. СТАТИСТИКА II: ИЗУЧЕНИЕ ВЗАИМОСВЯЗЕЙ МЕЖДУ ДВУМЯ ПЕРЕМЕННЫМИ
Чаще всего в политологических исследованиях мы заинтересованы в изучении распределений по одной переменной меньше, чем в определении того, взаимосвязаны ли две или более переменных и если да, то каким образом и насколько тесно. Именно эти двумерные (относящиеся к двум переменным) и многомерные (относящиеся к более чем двум переменным) взаимосвязи обычно проливают свет на самые интересные исследовательские вопросы.
Обычно при изучении взаимосвязей между двумя переменными встает три важнейших вопроса; вы, должно быть, помните о них из гл. 1. Первый заключается в том, влияют ли и до какой степени изменения значений одной переменной – обычно независимой переменной – на изменения значений другой – зависимой – переменной. Второй вопрос касается формы и направления любой связи, которая может существовать. Третий рассматривает возможность того, что любая взаимосвязь, существующая между признаками, которые представляют выборку из более крупной совокупности, действительно является характеристикой этой совокупности, а не просто артефактом меньшей и потенциально нерепрезентативной выборки. В этой главе мы познакомимся со статистическими приемами, которые чаще всего используются при ответах на эти вопросы, и объясним, когда правомерно их использование. [c.408]
ИЗМЕРЕНИЕ СВЯЗИ И СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТИ
В том случае, если знание значений одной переменной по определенному случаю позволяет сделать некоторые предположения относительно соответствующих значений другой переменной, между этими переменными существует связь 1. Если, например, мы исследуем взаимосвязь между численностью населения какой-либо страны и долей взрослых, получивших высшее образование (принимая во внимание, что мы располагаем такими данными), то возможны три вывода: (1) более крупные страны [c.408] обычно имеют большую долю взрослых, получивших высшее образование, чем менее крупные; (2) малые страны обычно имеют большую долю взрослых, получивших высшее образование, чем более крупные, и (3) систематических различий нет; некоторые страны из обеих групп имеют относительно высокую долю таких людей, а другие – тоже из обеих групп – относительно низкую. Если исследование покажет, что верен случай 1 или случай 2, то мы можем использовать знание значений независимой переменной – количество населения, – для того чтобы примерно представить или предсказать значения зависимой переменной – доля взрослых, получивших высшее образование – для любой из взятых стран. В первом случае для густонаселенных стран можно предсказать и относительно высокую долю взрослых с высшим образованием, а для малонаселенных стран – более низкую их долю. Во втором случае наши предположения будут прямо противоположны. В обоих случаях, хотя мы можем и не угадать каждый случай точно, мы будем чаще всего правы, поскольку между этими переменными существует связь. И конечно, чем теснее связь между двумя переменными, тем более вероятно, что наши догадки в каждом отдельном случае будут верны. Если существует полная зависимость значений одной переменной от значений другой, т. е. высокие значения одной переменной вызывают высокие значения другой или, наоборот, высокие значения одной вызывают низкие значения другой, мы можем вывести одну из другой с довольно большой степенью точности. Все это в корне отличается от третьего случая, который не позволяет с достаточной долей точности предугадать значения переменной образование, основываясь на знании количества населения. Если признаки по двум переменным распределяются, по сути дела, произвольно, то считается, что эти переменные не имеют связи.
Чтобы понять, как же выглядит эта самая “сильная связь”, рассмотрим две схематические карты, изображенные на рис. 15.5. (см. с. 434-435), которые представляют уровень убийств в Вашингтоне в 1988 г. На схеме 15.5а указаны известные рынки, производящие торговлю наркотиками в столице. На схеме 15.5б показаны места, где происходили убийства. Обе схемы отражают данные, полученные в городской полиции. Легко заметить, что [c.409] сосредоточение точек, обозначающих места продажи наркотиков и убийств, практически одинаково, и таким образом выявляется связь между двумя этими феноменами.
Понятно, что между переменными может существовать более или менее сильная связь. Естественно, возникает вопрос, насколько сильна эта связь. На помощь приходит статистика. Из статистики возьмем показатель, который называется коэффициентом связи. Коэффициент связи – это показатель, который обозначает степень возможности определения значений одной переменной для любого случая, базируясь на значении другой. В нашем примере этот коэффициент может показать, насколько знание количества населения страны поможет в определении доли взрослых, получивших высшее образование. Чем больше коэффициент, тем сильнее связь и, следовательно, выше наши возможности прогноза. Вообще коэффициент колеблется в переделах от 0 до 1 или от –1 до 1, где значения, близкие к единице, обозначают относительно сильную связь, а значения, близкие к 0, – относительно слабую. Как было в случае с одномерной статистикой – и по тем же причинам, – каждый уровень измерения требует своего типа исчислений, и поэтому каждый из них требует своего способа измерения связи.
В дополнение к величине связи полезно также знать направление или форму взаимоотношений между двумя переменными. Еще раз обратите внимание на вышеприведенный пример, особенно на варианты 1 и 2. Мы уже предположили, что, чем теснее связаны признаки, тем больше будет коэффициент связи и тем выше шансы угадать долю взрослых с высшим образованием на основании знаний о количестве населения в данной стране. Очевидно, однако, что наши прогнозы относительно каждого случая будут совершенно противоположны. В первом случае большие значения одной переменной вероятнее всего связаны с большими значениями другой, тогда как во втором случае большие значения одной переменной вероятнее всего связаны с меньшими значениями другой. Такие связи называются связями, имеющими разное направление. А такой тип связей, как в первом случае, когда обе переменные возрастают и убывают одновременно, называется прямой, или положительной, связью. Тип связей второго случая, когда значения постоянно изменяются в [c.410] разных направлениях, называется обратной, или отрицательной, связью. Эта добавочная информация – о знаке (плюс или минус) перед коэффициентом связи – способна сделать наши предположения более эффективными. Таким образом, коэффициент, равный –0,87 (отрицательный и близкий к единице), может описывать относительно сильную взаимосвязь, в которой значения двух данных переменных обратно связаны (изменяются в разных направлениях), коэффициент же, равный 0,10 (положительный – знак “плюс” обычно опускают – и близкий скорее к 0), может описывать слабую прямую связь.
Для всех случаев понятие направления или формы имеет разный смысл для разных уровней измерения. На номинальном уровне, где цифры играют роль просто обозначений, концепция направления вообще не имеет смысла и, соответственно, номинальные коэффициенты связи не изменяют знака. Все они положительны и просто показывают силу связи. На интервальном же уровне, наоборот, знаки могут не только изменяться, но и иметь достаточно сложную геометрическую интерпретацию. Проверка на связь на этом уровне измерений обладает очень высокими прогностическими способностями, причем знак коэффициента является в этом случае ключевым элементом.
Наконец, несколько слов о проверке статистической значимости, хотя обсуждение этого сюжета будет сознательно ограничено2. Если мы делаем предположительно репрезентативную выборку некоторого определенного размера и используем эту выборку для формулирования каких-то выводов о той генеральной совокупности, из которой она была сделана, мы несколько рискуем получить неверные выводы. Это так, потому что существует вероятность, что выборка, по сути дела, нерепрезентативна и что в действительности ошибка измерений превышает уровень, допустимый для выборки данного размера (см. табл. А.2 и А.3 в приложении А). Вероятность подобных неверных обобщений в принципе известна, однако в каждом отдельном случае мы не всегда можем сказать, имеются они или нет. Для доверительного уровня 0,95 вероятность этого составит 0,05 или 1 – 0,95, для доверительного уровня 0,99 – 0,01. Эти величины 0,05 и 0,01 или 5% и 1% свидетельствуют о том, что любое обобщение, [c.411] сделанное по выборке и относящееся к генеральной совокупности, даже подпадающее под подсчитанный уровень ошибки выборки, просто-напросто неверно.
Проверки на статистическую значимость играют ту же роль для оценки измерений связи. Они определяют, насколько вероятна связь, зафиксированная между двумя признаками в выборке. Давайте попробуем пояснить этот пункт.
Продолжая наш пример, представьте, что у нас есть совокупность из 200 стран, для которых доподлинно известно, что коэффициент связи между количеством населения и долей взрослых, получивших высшее образование, равен 0, т. е. в реальности такой связи нет. Представьте далее, что в силу тех или иных причин мы считаем необходимым взять выборку только в 30 стран и подсчитать для них связь между этими двумя переменными. Он также может оказаться равным 0, но в действительности это маловероятно, поскольку сила связи теперь зависит не от всех 200 стран, а только от 30 и, возможно, будет отражать их характерные особенности. Другими словами, величина коэффициента предопределена тем, какие именно 30 стран мы выберем. Если случайно мы выберем те 30 стран, которые действительно репрезентативны относительно всех 200, связь не обнаружится. Но тот же случай может привести нас к тому, что мы выберем такие 30 стран, для которых связь между количеством населения и уровнем образования необычайно высока, скажем 0,60. В этом случае наш подсчитанный со всей тщательностью коэффициент будет характеризовать данную выборку, но, если мы распространим эту характеристику на генеральную совокупность, наши выводы будут неверны. Зная это, конечно, необходимо отвергнуть измерение связи на основании именно этой выборки.
Проблема заключается в том, что в действительности мы не знаем глубинные параметры совокупности, например истинную степень связи признаков в ней. Безусловно, причина, по которой мы вынуждены прибегать к выборкам, прежде всего в том, что мы просто не в состоянии изучать совокупности в целом. А отсюда в свою очередь следует, что чаще всего мы будем иметь в распоряжении только те проверки связей, которые основаны на выборках. Более того, эти подсчеты будут основаны только на одной выборке. Тогда встает вопрос, насколько можно [c.412] быть уверенным в том, что проверка связей, основанная на единственной подгруппе генеральной совокупности, точно отражает глубинные характеристики этой совокупности. Задача проверки на статистическую значимость и заключается в том, чтобы дать цифровое выражение этой уверенности, измерить возможность или вероятность того, что мы делаем верные, или, наоборот, неверные обобщения.
Для того чтобы увидеть, как все это работает, давайте продолжим наш пример. Представьте, что мы сделали не одну выборку в 30 стран из всей совокупности в 200 стран, а 100 или даже 1000 отдельных и независимых выборок равного размера и что для каждой подсчитан коэффициент связи. Поскольку верный для всей совокупности коэффициент, по сути, равен 0, большинство коэффициентов в наших 100 или 1000 выборках тоже будут равны 0 или близки к этому. Они ведь, кроме всего прочего, основаны на измерении характеристик одних и тех же стран в конце концов. Некоторые комбинации из 30 стран могут показать относительно высокие значения (это если нам случайно удастся выбрать те страны, где эти переменные связаны по типу высоких или низких связей), но большинство будет близким к параметрам всей совокупности. Безусловно, чем ближе к истинному значению коэффициента, тем большее количество выборок будет его иметь. Эти распределения, по сути дела, будут всегда располагаться по нормальной кривой, которую мы упомянули ранее. Это показано на рис. 15.1, где высота кривой в любой точке представляет количество выборок, для которых коэффициент связи имеет значение, отмеченное на оси ординат.
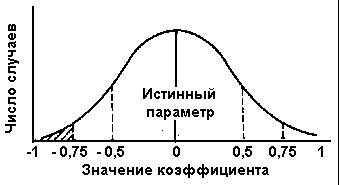
Рис. 15.1. Кривая нормального распределения для коэффициента для выборки из 30 случаев.
Какова же тогда вероятность того, что любое значение коэффициента – это просто случайное отклонение от истинного нулевого параметра? Или, другими словами, если мы возьмем выборку из какой-нибудь совокупности и выявим в этой выборке устойчивую связь, но при. этом нам не будут с определенностью известны соответствующие характеристики всей совокупности, каковы шансы того, что мы ошибемся, перенося такую сильную связь с выборки на всю совокупность? Нормальная кривая имеет некоторые особенности, которые мы не будем здесь обсуждать, не позволяющие нам ответить на этот вопрос с достаточной точностью. [c.413]
Представьте, к примеру, что мы сделали из генеральной совокупности в 200 стран выборку в 30 стран, для которых коэффициент связи равен –0,75, а глубинных параметров мы не знаем. Насколько вероятно, что соответствующий коэффициент для всей совокупности будет равен 0? Исходя из рис. 15.1, ответ должен звучать: не очень. Часть плоскости, заключенная под графиком, представляет все 100 или 1000 (собственно, любое количество) коэффициентов, при этом истинный коэффициент равен 0. Меньшая ее часть – левее значения –0,75 – представляет долю таких коэффициентов, которые отрицательны по направлению и более или равны 0,75 по значению. Эти случаи составляют очень маленькую часть от всех коэффициентов выборок. По этой причине шансы того, что при любой попытке сформировать выборку мы сделаем именно такую выборку, очень малы. Если в этой области лежит, например, 5% всех выборок, то только один раз из 20 может случиться так, что из всей совокупности с истинным коэффициентом, равным 0, мы сделаем выборку с коэффициентом –0,75. Тем не менее в данном случае мы имеем именно такую выборку. Другими словами, мы сделали выборку с такими характеристиками, которые имеют 5%-ную вероятность быть ошибочным отражением совокупности, где две рассматриваемые переменные не связаны друг с другом. Таким образом, если на основании этой выборки мы сделали вывод, что на самом деле эти две [c.414] переменные связаны друг с другом в генеральной совокупности (т.е. если мы интерполировали результаты, полученные на основании выборки), то следует ожидать, что на 5% мы не правы. Конечно, это же значит, что на 95% мы правы, а это неплохие шансы. И конечно, уровни статистической значимости в 0,05 (5%-ная вероятность ошибок), 0,01 (1%-ная вероятность ошибок) и 0,001 (0,1 от 1%-ной вероятности ошибок) – это общепринятые стандарты в политологических исследованиях.
Если мы опять взглянем на рис. 15.1, станет ясно, что более экстремальные значения, такие, как –0,75, реже способны дать заметную ошибку при обобщениях, чем те, которые расположены ближе к центру (например, гораздо большая доля выборок из этой группы покажет коэффициенты, равные и превышающие –0,50 и т. д.). В конце концов может показаться, что никогда нельзя быть уверенным в правильности утверждения о наличии слабых связей, поскольку никогда нельзя устранить достаточно большую вероятность того, что они просто случайно появились в совокупности с истинным нулевым коэффициентом. Однако вполне возможно решить эту проблему простым увеличением размеров выборки. Если вместо 30 признаков мы включим в выборку 100 или 150, мы не только будем располагать меньшим количеством выборок для начала расчетов, но и при наличии истинного коэффициента они вероятнее всего будут располагаться вокруг нулевого значения. По сути дела, нормальная кривая будет постоянно стремиться к сжатию в середине, как изображено на рис. 15.2, пока не придет в конце концов к единственно возможному варианту – истинному параметру. [c.415]
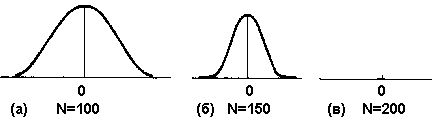
Рис. 15.2. Распределение выборки разного размера при генеральной совокупности, равной 200 случаям
По ходу дела все меньше и меньше предельных значений будут располагаться по краям кривой, пока наконец при достаточно больших выборках даже коэффициенты связи со значением 0,10 или 0,01 не покажут приемлемый уровень статистической значимости. Теперь мы можем сделать вывод, что определенные сочетания достаточно экстремальных значений и достаточно больших выборок позволяют нам уменьшить до допустимого уровня вероятность неверных обобщений по нашим данным.
Однако не всегда коэффициенты связи распределяются нормально и не все проверки статистической значимости производятся по такой же логической схеме. Но в большинстве случаев принцип тот же, и если вы поняли его, то вы поймете как необходимость, так и пользу измерения статистической значимости.
В этой главе мы также кратко обсудим наиболее распространенные способы измерения связи и значимости для каждого из трех уровней измерений. При этом если процедуры, необходимые для подсчета каждого из трех измерений будут различными, то цель в каждом случае, так же как и интерпретация результатов, окажется примерно одинаковой, поскольку любой вид коэффициента связи призван показать нам, до какой степени наши предположения относительно значений одной переменной могут определяться знанием значений (имеется в виду по тем же случаям) другой, а каждая проверка значимости говорит о том, насколько вероятно (возможно), что любые наблюдающиеся в выборке связи возникают вследствие выборочных процедур, а не являются отражением истинного положения дел в генеральной совокупности. Нигде эти двойные функции не становятся более очевидными, как в статистических измерениях базового типа– номинальных.
Примеры, иллюстрирующие эту статистику, подразумевают сравнение переменных, которые используются на одном уровне измерения. Однако исследователи часто хотят найти соотношения между переменными, находящимися на разных уровнях измерения (таких, как одноуровневая независимая переменная, например, социоэкономический статус и зависимая номинальная переменная – партийная принадлежность). Чтобы выбрать правильную статистику для этого случая, вам необходимо придерживаться простого правила: использовать статистику, разработанную для низшего уровня измерений, не игнорируя [c.416] при этом данные для измерений высококачественного уровня. Вполне законно вы можете применять статистику для номинальных признаков с одноуровневыми данными, но совершенно невозможно использовать одноуровневую статистику для номинальных измерений. Это означает, что, когда вы проводите сравнение переменных, которые измеряются на разных уровнях, вы должны так выбирать статистический критерий, чтобы он соответствовал нижнему из двух уровней. [c.417]
ИЗМЕРЕНИЕ СВЯЗИ И ЗНАЧИМОСТИ ДЛЯ НОМИНАЛЬНЫХ ПЕРЕМЕННЫХ
Широко используемым коэффициентом связи для номинальных переменных, из которых одна считается зависимой, а другая – независимой, является λ (лямбда)3. Лямбда измеряет процентную долю того, насколько возможно угадывание значений зависимой переменной на основе знаний независимой переменной, если обе переменные представлены категориями, не содержащими ранга, интервала или направления.
Представьте, например, что мы определяем партийную принадлежность 100 респондентов и выясняем, что частотное распределение выглядит следующим образом:
|
|
Демократы |
50 |
|
Представьте также, что мы хотим установить партийную принадлежность каждого отдельного респондента и сделать подобные предположения для всех лиц и что мы хотим при этом совершить минимум ошибок. Наиболее очевидный путь – определить моду (самую распространенную категорию); мы предполагаем, что это будут демократы. Мы окажемся правы в 50 случаях (для 50 демократов) и не правы в 50 случаях (для 30 республиканцев и 1 независимых); это не просто стоящее внимания замечание, но самое лучшее, что мы можем сделать, поскольку ни мы выберем республиканцев, то окажемся не правы 170 случаях, а если выберем независимых, то это приведет к 80 неверным предположениям. Таким образом, данная [c.417] мода обеспечивает наилучший уровень предположений для имеющейся в распоряжении информации.
Но мы можем располагать еще одним набором данных, партийной принадлежности отца каждого респондента, представленным следующим распределением:
|
|
Демократы |
60 |
|
Если эти две переменные связаны друг с другом, т. е. если каждый отдельный респондент вероятнее всего принадлежит к той же партии, что и ее (или его) отец, то знание партийных предпочтений отца каждого респондента может помочь нам в определении партийных предпочтений самих респондентов. Это будет так в том случае, если, определяя для каждого респондента не моду всего распределения, как мы делали прежде, а просто партийную принадлежность его (или ее) отца, мы сможем снизить количество неверных предположений до уровня более низкого, чем 50 неверно определенных нами случаев.
Чтобы это проверить, нужно построить таблицу сопряженности, подытоживающую распределение признаков по этим двум переменным. В табл. 15.1 независимая, или определяющая, переменная (партийная принадлежность отца) дана по рядам, ее итоговое распределение находится в правой части таблицы. Зависимая переменная (партийная принадлежность респондента) расположена по колонкам, и ее итоговое распределение находится в низу таблицы. Значения в таблице даны произвольно, и в действительности они, конечно, должны пересчитываться самим исследователем.
Таблица 15.1.
Определение партийности на основании партийной принадлежности отца (1)
|
Партийность отца |
Партийность респондента |
|||
|
Демократ |
Республиканец |
Независимый |
Всего |
|
|
Демократ |
45 |
5 |
10 |
60 |
[c.418]
По этой таблице мы можем партийные предпочтения родителей использовать для определения партийных предпочтений респондентов. Для этого мы, как и раньше, определим моду, но только внутри каждой категории независимой переменной, а не по всему набору признаков. Таким образом, получится, что для тех респондентов, чьи отцы зафиксированы как демократы, мы прослеживаем предпочтение той же партии. Мы будем правы 45 раз и не правы 15 (для 5 республиканцев и 10 независимых). Для тех, чьи отцы зафиксированы республиканцами, мы предполагаем принадлежность к республиканской партии, при этом в 23 случаях мы окажемся правы и в 7 – не правы. Тех, чьи отцы зафиксированы независимыми, отнесем к независимым и будем правы в 5 из 10 случаев. Сравнив эти результаты, увидим, что теперь мы в состоянии верно предположить 73 раза и все еще ошибаемся 27 раз. Иными словами, наличие второй переменной существенно улучшило наши шансы. Для того чтобы точно определить процентную долю этого улучшения, используем общую формулу коэффициента связи.
![]()
![]()
В приведенном примере это выглядит так:
![]()
Используя партийную принадлежность отца в качестве определителя партийной принадлежности респондента, мы можем улучшить (ограничить количество ошибок) наши предположения примерно на 46%.
Формула подсчета λ, которая приведет нас к тем же результатам, хотя и несколько другим путем, такова:
![]() ,
,
[c.419]
где fi – максимальная частота внутри каждой категории или градации независимой переменной;
Fd – максимальная частота в итоговых распределениях зависимой переменной;
N – количество признаков.
Лямбда изменяется в пределах от 0 до 1, где высшие (близкие к 1) значения обозначают сильную связь. Поскольку номинальные переменные не имеют направления, λ всегда будет положительной.
Следующий наш шаг – определить, чем вызваны взаимосвязи, выраженные λ, – истинными параметрами совокупности или просто случаем, т.е. мы должны определить, являются ли эти взаимосвязи статистически значимыми.
Для номинальных переменных тест на статистическую значимость проводится путем подсчета критерия χ2 (хи-квадрат). Этот коэффициент говорит нам о том, насколько вероятно, что номинальный тип связей, который мы только что наблюдали, является результатом случая. Это делается путем сравнения тех результатов, которые мы реально имеем, с теми, которые ожидаются тогда, когда между переменными нет никакой связи. Подсчет χ2 также начинается с таблицы взаимной сопряженности признаков, хотя и несколько отличающейся от табл. 15.1. Рассмотрим табл. 15.2.
Таблица 15.2.
Определение партийности на основании партийной принадлежности отца (2)
|
Партийность отца |
Партийность респондента |
|||
|
Демократ |
Республиканец |
Независимый |
Всего |
|
|
Демократ |
|
|
|
60 |
Эта таблица напоминает табл. 15.1 тем, что категории переменных те же самые, но табл. 15.2 не содержит никаких распределений в своих графах. Определение χ2 начинается с того, что мы задаем себе вопрос: какое значение мы ожидаем в каждой графе при [c.420] имеющихся итоговых распределениях, если между переменными нет связи? Для 60 респондентов, чьи отцы были демократами, например, мы можем ожидать, что половина (50/100) будут демократами, около трети (30/100) будут республиканцами и один из 5 (20/100) – независимым, или, другими словами, 30 демократов, 18 республиканцев и 12 независимых.
Точно так же мы можем прикинуть ожидаемые значения для тех, у кого отцы были республиканцами или независимыми. Эти ожидаемые значения собраны в табл. 15.3.
Таблица 15.3.
Определение партийности на основании партийной принадлежности отца (3)
|
Партийность отца |
Партийность респондента |
|||
|
Демократ |
Республиканец |
Независимый |
Всего |
|
|
Демократ |
30 |
18 |
12 |
60 |
Тогда встает вопрос: действительно ли значения табл. 15.1 настолько отличаются от тех значений, которые можно предположить в табл. 15.3, что мы можем быть решительно уверены в надежности наших результатов? Хи-квадрат и является тем инструментом, который посредством сравнения двух таблиц даст ответ на наш вопрос. Уравнение для χ2 выглядит следующим образом:
![]() ,
,
где f0 – частота, наблюдаемая в каждой графе (см. табл. 15.1);
fe – частота, ожидаемая в каждой графе (см. табл. 15.3).
Подсчитывается χ2 путем внесения значений в каждую графу табл. 15.4. [c.421]
Таблица 15.4.
Значения, используемые для получения χ2
|
f0 |
fe |
f0 –fe |
(f0 –fe)2 |
(f0 –fe)2 |
|
45 |
30 |
15 |
225 |
7,5 |
Порядок граф таблицы не имеет значения, но f0 из табл. 15.1 и fe из табл. 15.3 в каждой определенной строке должны относиться к одному и тому же случаю. Причина того, что разность между f0 и fe сначала возводится в квадрат и лишь потом делится на fe, та же, что в случае колебаний вокруг среднего геометрического при определении стандартного отклонения. Хи-квадрат определяется путем сложения всех цифр в последней колонке. В нашем примере он получает значение 56,07.
Прежде чем мы интерпретируем эту цифру, нам необходимо сделать еще одно вычисление – подсчитать так называемые степени свободы (degrees of freedom – df). Степени свободы в таблице – это количество ячеек таблицы, которые могут быть заполнены цифрами, прежде чем содержание всех остальных ячеек станет фиксированным и постоянным. Формула для определения степеней свободы в любой определенной таблице такова:
df = (r – 1) (c – 1),
где r = количество категорий переменной в ряду;
с = количество категорий переменной в колонке.
Например, df = (3 – 1) (3 – 1) = 4.
Теперь мы готовы оценить статистическую значимость наших данных. Таблица А.4 в приложении содержит [c.422] значимые величины χ2 для различных степеней свободы на уровнях 0,001; 0,01; 0,05. Если значение χ2, которое мы подсчитали (56,07), превышает то, что указано в таблице на любом из этих уровней для таблицы с определенными степенями свободы (4), то можно сказать, что те взаимосвязи, которые мы наблюдали, на данном уровне статистически значимы. В настоящем случае, например, для того чтобы связь была значимой на уровне 0,001 (т.е. если мы допускаем, что наблюдаемая связь отражает характеристики всей совокупности, то мы рискуем ошибиться один раз из 1000), наблюдаемый χ2 должен превышать 18,467. Если это так, то мы можем быть абсолютно уверены в своих результатах. [c.423]
ИЗМЕРЕНИЕ СВЯЗИ И ЗНАЧИМОСТИ ДЛЯ ПОРЯДКОВЫХ ПЕРЕМЕННЫХ
Для порядковых переменных чаще всего используется коэффициент связи G, или гамма, работающий по тому же принципу ограничения ошибки, что и λ , но особо ценный тем, что он не просто определяет количество признаков в той или иной категории, а ранжирует их, т.е. выясняет их относительную позицию. Вопрос, решаемый с помощью G, состоит в том, какова степень, до которой ранжирование случаев одной порядковой переменной может быть определено при условии знания рангов случаев другой порядковой переменной.
Когда мы анализируем две подобные переменные, то возможны два случая зависимости. Первый, при котором случаи ранжируются в одном и том же порядке в обеих переменных (большие значения – с большими, меньшие – не меньшими), называется полное согласие. Второй, в котором случаи расположены в прямо противоположном порядке (большие значения одной переменной связаны с меньшими значениями другой и наоборот), называется полная инверсия. Тогда возможность предсказания (т.е.степень связи между двумя переменными) будет следствием того, насколько тесно ранги одной переменной связаны с рангами другой либо по типу “полное соответствие” (если G положительна и приближается к единице), либо но типу “полная инверсия” (если G отрицательна и приближается к –1). Значение коэффициента G, равное 0, [c.423] свидетельствует об отсутствии связи. Формула для исчисления G такова:
![]()
где fа = частота соответствий в ранжировании двух переменных;
fi = частота инверсий в ранжировании двух переменных.
G основана на относительном расположении набора случаев по двум переменным. Случаи сначала располагаются в восходящем порядке по независимой переменной. Затем это сравнивается с порядком расположения по зависимой переменной. Считается, что те переменные, для которых заданный порядок сохраняется, находятся в соответствии, а те, для которых этот порядок меняется на противоположный, связаны по типу инверсии. Недостаток места не позволяет нам рассмотреть эти процедуры детально или обсудить способы подсчета G для вариантов, когда количество признаков мало и/или между рангами не встречается одинаковых значений (параллелей). Лучше мы подробнее остановимся на процедурах, необходимых для подсчета G для более распространенных условий: когда есть параллели (более одного признака с одним и тем же рангом), а само количество признаков достаточно велико4.
Здесь, как и ранее, следует обратиться к таблице взаимной сопряженности признаков, такой, какой является табл. 15.5.
Таблица 15.5.
Обобщенная таблица взаимной сопряженности признаков
|
Значения независимой переменной |
Значения зависимой переменной |
||
|
низкие |
средние |
высокие |
|
|
Низкие |
a |
f |
c |
Для того чтобы измерить связь между этими двумя переменными, необходимо определить количество соответствий и инверсий, относящихся к каждой ячейке таблицы. [c.424] Соответствия расположены во всех ячейках под (по направлению к более высоким значениям независимой переменной) и справа (по направлению к более высоким значениям зависимой переменной) от любой определенной ячейки. Так, соответствия относительно случаев ячейки о включают все случаи в ячейках e, f, h и i, поскольку эти случаи имеют более высокие ранги, чем случаи ячейки a по обеим переменным. Инверсии расположены во всех ячейках под (по направлению к более высоким значениям независимой переменной) и слева (по направлению к более низким значениям зависимой переменной) от любой определенной ячейки. Так, инверсии относительно случаев ячейки с включают все случаи в ячейках d, е, g и h поскольку это случаи более высоких по сравнению с ячейкой с значений по одной переменной и более низких – по другой. Частота соответствий (fа в уравнении), таким образом, для каждой ячейки есть сумма всех случаев по каждой ячейке, умноженных на количество случаев во всех ячейках ниже и справа (a[e+f+h+i]+b[f+i]+e[i]). Частота инверсий (fi в уравнении) – это сумма всех случаев по каждой ячейке, умноженная на количество случаев во всех ячейках ниже и слева (b[d+g]+c[d+e+g+h]+f[g+h]). Полученные значения просто подставляются в уравнение.
fa = 45(23+5+2+5)+5(5+5)+2(2+5)+23(5) = 1575+50+14+115 = 1754
fi = 5(2+3)+10(2+23+3+2)+23(3)+5(3+2) = 25+300+69+25 = 419
![]()
Эта цифра говорит о том, что во взаимном расположении двух переменных на 61% больше соответствий, чем несоответствий. Если fi превышает fа, G будет иметь отрицательный знак, что означает наличие инверсионного типа взаимосвязей.
Проверка статистической значимости коэффициента основана на том факте, что распределение G в выборке из совокупности, где нет значимых связей, приближается к нормальному, так же как распределение гипотетического коэффициента в выборке, которую мы обсуждали раньше. Если это так, то мы можем проверить, не является ли [c.425] любое конкретное значение G следствием случайности, путем вычисления его стандартной оценки (z), определения ее расположения под нормальной кривой и оценки таким образом этой возможности. Целиком подсчет zG (стандартной оценки гаммы) здесь не будет представлен, поскольку формула сложна и ее понимание требует более детального знания статистики по сравнению с уровнем нашей книги. Некоторые сведения о формуле можно найти в книге Фримана (см. прим. 1), и ее подсчет предусмотрен такими пакетами прикладных программ, как SPSS. Достаточно сказать, что когда G превышает ±1645 (когда G удалена от медианы на 1645 единиц стандартного отклонения), G достаточна, чтобы иметь доверительный уровень в 0,05, а если zg превышает ±2326 (когда G удалена от медианы в том или ином направлении на 2326 единиц стандартного отклонения), G достигает значимости на уровне 0,01. Интерпретация этих результатов та же, что в приведенном выше, более общем примере. [c.426]
ИЗМЕРЕНИЕ СВЯЗИ И ЗНАЧИМОСТИ ДЛЯ ИНТЕРВАЛЬНЫХ ПЕРЕМЕННЫХ
Измерение связи между двумя интервальными переменными осуществляется посредством корреляции произведения моментов Пирсона (r), известной также как коэффициент корреляции. Этот коэффициент описывает силу и направление связей, используя те же принципы, что и ранее, – относительное ограничение ошибки в предположениях о значениях одной переменной на основе данных о значениях другой, хотя способ, которым это делается, равно как и тип данных, для которых предназначен этот коэффициент, гораздо более сложен, чем все другие, обсуждавшиеся нами ранее. Здесь в отличие от использования среднего геометрического зависимой переменной (обозначаемой Y) для подсчета значений отдельных признаков используется ее геометрическая взаимосвязь с зависимой переменной (обозначаемой обычно X). Если точнее, мы основное внимание уделяем той помощи, которую может оказать уравнение линейной зависимости в определении значений Y на основе сведений о соответствующих значениях X.
Подсчет r начинается с изучения диаграммы рассеяния, графического изображения распределения случаев [c.426] по двум переменным, где горизонтальная линия, или ось X, шкалирована в единицах независимой переменной, а вертикальная линия, или ось У, шкалирована в единицах зависимой переменной и каждая точка представляет расположение одного случая относительно обеих переменных. Такая диаграмма представлена на рис. 15.3, где независимая переменная – это возраст, зависимая переменная – количество законченных лет обучения, а количество случаев равно 25. Так, заключенная в кружок точка представляет следующий случай: человек 30 лет, проучившийся 10 лет. На рисунке цифры взяты произвольно, но в практической работе значения должны определяться самим исследователем.
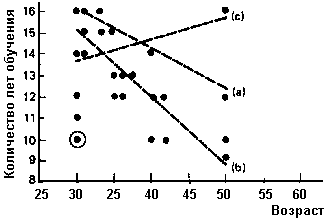
Рис. 15.3. Диаграмма рассеяния, показывающая взаимосвязь между возрастом и количеством лет обучения
Следующий шаг – провести через это множество точек прямую, которая называется линией регрессии, так, чтобы ни одна другая линия не смогла бы пройти ближе ко всем точкам (и хотя, как мы увидим, такие линии не определяют, просто глядя на картинку, ясно, что из всех прямых на рисунке – а, b и с – прямая b наиболее близка к такой линии). Такая наиболее подходящая линия для двух взаимоувязанных переменных аналогична среднему геометрическому в одномерных описательных статистиках. Точно так же геометрическое представляет наиболее типичный случай в частотном распределении, линия регрессии представляет наиболее типичную связь между двумя переменными. Точно так же, как мы могли [c.427] использовать среднее геометрическое для определения значений переменной при отсутствии дополнительной информации, мы можем использовать линию регрессии для определения значений одной переменной на основании сведений о значениях другой. Если, например, нам известно значение X для данного случая, мы можем провести вертикаль от этой точки на оси до пересечения с линией регрессии, затем – горизонтальную линию до пересечения с осью Y. Точка пересечения с осью Y и даст предполагаемое значение Y.
Но точно так же, как среднегеометрическое может быть единственным наиболее типичным значением, но не очень хорошо при этом отражать распределение в целом, так и линия регрессии может наилучшим образом обобщать взаимозависимость двух переменных, но не быть при этом очень полезным обобщением. И соответственно так же, как мы используем стандартное отклонение (s) в качестве меры дисперсии или близости к среднему геометрическому, мы используем коэффициент корреляции, или более полно соответствующий требованиям интерпретации этот коэффициент, возведенный в квадрат (r2), в качестве меры близости различных точек, обозначающих наши данные, к линии регрессии. По сути дела, это мера того, насколько типично отражает эта линия обобщенное распределение значений по двум переменным. В тех случаях, когда все точки лежат точно на этой линии, как на рис. 15.4а и 15.4д, она наилучшим образом описывает взаимосвязь между двумя переменными. Если точки в целом сгруппированы в направлении, обозначенном линией, но не лежат точно на ней, как на рис. 15.4б и 15.4г, то линия представляет взаимосвязи между этими переменными лишь приблизительно. И если, как на [c.428] рис. 15.4в, не существует линии, которая расположена ближе к точкам, чем любая другая, между переменными не существует связи5.
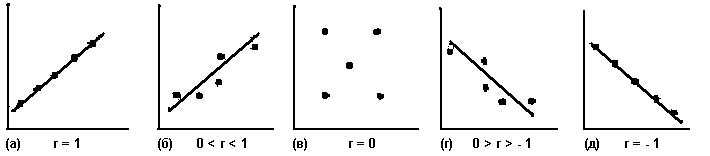
Рис. 15.4. Линии регрессии при различных значениях r
Проблема, таким образом, имеет двойственный характер: во-первых, как выглядит эта наиболее подходящая линия? И во-вторых, насколько точно она отражает данные?
Вы, должно быть, помните из курса алгебры, что любая прямая имеет формулу:
Yi = a + bXi,
где а – значение Y при Х= 0,
b – коэффициент наклона прямой,
Х – соответствующее значение независимой переменной.
Линия регрессии (обычно обозначается Y’, чтобы показать, что это лишь приблизительное отражение истинного распределения) – это просто набор предполагаемых значений, выраженных в такой форме, которая является наилучшей для значения Y, основанных на знании значений X.
По причинам, которые мы здесь не будем обсуждать, коэффициент наклона прямой всегда будет выражаться формулой:
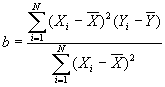 ,
,
где Хi и Yi – соответствующие значения независимой и зависимой переменных для случая i, a ![]() и
и ![]() – соответствующие средние геометрические. Заметьте, что коэффициент b основан на разбросе отдельных случаев вокруг двух средних геометрических (т. е. на [Xi –
– соответствующие средние геометрические. Заметьте, что коэффициент b основан на разбросе отдельных случаев вокруг двух средних геометрических (т. е. на [Xi – ![]() ] и [Yi –
] и [Yi – ![]() ]). Применив эту формулу и используя схему, подобную той, которую мы применяли при подсчетах χ2, мы сможем определить угол наклона для любых взаимосвязей между двумя интервальными переменными. Этот способ показан в табл. 15.6 на примере данных использованных в рис. 15.3. Для этих данных
]). Применив эту формулу и используя схему, подобную той, которую мы применяли при подсчетах χ2, мы сможем определить угол наклона для любых взаимосвязей между двумя интервальными переменными. Этот способ показан в табл. 15.6 на примере данных использованных в рис. 15.3. Для этих данных![]() = 37,08 и
= 37,08 и ![]() = 12,88. Подставив эти значения в уравнение, получим:
= 12,88. Подставив эти значения в уравнение, получим:
![]()
[c.429]
Таблица 15.6.
Значения, используемые для вычислений по уравнению регрессионной прямой
|
Хi |
(Хi – |
(Хi – |
Yi |
(Yi – |
(Хi– |
|
30 |
–7,08 |
50,13 |
10 |
–2,88 |
20,39 |
При линейной зависимости, т. е. такой, которая может быть представлена прямой линией, любое определенное изменение независимой переменной всегда вызывает определенное изменение значений зависимой переменной У. Более того, при таких зависимостях норма изменения постоянна, т. е. независимо от конкретных значений X и Y каждое изменение Х на единицу вызовет некоторое определенное изменение Y, размер которого определен степенью наклона линии регрессии. Зависимости, при которых небольшие изменения Х вызывают относительно [c.430] большие изменения Y, изображаются линиями, имеющими сравнительно крутой наклон (b1). Зависимости, при которых большие изменения X вызывают меньшие изменения Y, изображаются прямыми с относительно пологим наклоном (b). Зависимости, при которых изменение Х на единицу вызывает изменение Y на единицу, изображаются прямыми, для которых b=1. Прямые, направленные вверх слева направо, как на рис. 15.4а и 15.4б, имеют положительный наклон и представляют зависимости, в которых увеличение Х вызывает увеличение Y. Прямые, направленные вниз слева направо, как на рис. 15.4г и 15.4д, имеют отрицательный наклон и представляют зависимости, в которых увеличение X вызывает уменьшение Y. Ясно, что угол наклона прямой – это просто норма изменения переменной Y на единицу изменения переменной X, т.е. в нашем примере, где b=0,12, линия регрессии будет направлена вниз слева направо и, если обе переменные изображены в одном масштабе, будет относительно пологой.
Для того чтобы прийти к формуле, которую мы использовали для подсчета наклона линии регрессии, нам необходимо принять, что линия проходит через пересечение средних геометрических переменных и Y. Это – разумное допущение, поскольку средние геометрические представляют основную тенденцию этих переменных и поскольку мы, в сущности, ищем обобщенную или объединенную тенденцию. Если оба геометрических средних нам известны, а значение b определено, мы легко может найти значение а (точки, в которой линия регрессии пересекает ось Y) и решить уравнение. Общее уравнение регрессии таково:
Y’= a + bXi,
а в точке, где линия регрессии проходит через пересечение двух средних геометрических, оно принимает вид:
![]() = a + bХ.
= a + bХ.
Из этого следует, что
a = ![]() –
b
–
b![]()
Поскольку теперь мы знаем все нужные значения, мы можем определить, что [c.431]
а = 12,88–(–0,12)(37,08)= 12,88+4,45= 17,33.
Таким образом, уравнение регрессии, наилучшим образом подытоживающее распределение линии для данных, представленных на рис. 18.3, будет выглядеть так:
Y’ = 17,33–0,12Х.
Используя это уравнение, мы можем вычислить значение Y для любого конкретного значения.
Поскольку это уравнение решено, мы можем использовать коэффициент корреляции (r) для оценки репрезентативности линии регрессии. Формула rXY (коэффициента корреляции между X и Y) такова:
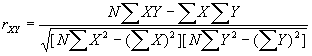 ,
,
где Х – каждое значение независимой переменной (знак i применялся ранее для большей наглядности);
Y – каждое значение зависимой переменной;
N – количество признаков.
Хотя это утверждение, безусловно, не так уж очевидно, а его алгебраическое доказательство лежит за рамками нашей книги, эта рабочая формула получена из сравнения первичной ошибки в предполагаемых значениях Y с использованием ![]() среднего геометрического частотного распределения с реальной ошибкой, получившейся в результате определения значений Y с использованием Y' (уравнения линии регрессии). Таким образом, процедура подсчета r аналогична той, которая использовалась для подсчета как l, так и G. Наилучшим образом ее дополнит построение таблицы такого типа, с которой мы уже знакомы; в ее колонках расположены значения X, Y, XY, X2 и Y2. Суммы, которые и нужны в уравнении, расположены в графе итого. Так, для данных, представленных на рис. 15.3, для которых мы уже определили линию регрессии, такой схемой будет табл. 15.7.
[c.432]
среднего геометрического частотного распределения с реальной ошибкой, получившейся в результате определения значений Y с использованием Y' (уравнения линии регрессии). Таким образом, процедура подсчета r аналогична той, которая использовалась для подсчета как l, так и G. Наилучшим образом ее дополнит построение таблицы такого типа, с которой мы уже знакомы; в ее колонках расположены значения X, Y, XY, X2 и Y2. Суммы, которые и нужны в уравнении, расположены в графе итого. Так, для данных, представленных на рис. 15.3, для которых мы уже определили линию регрессии, такой схемой будет табл. 15.7.
[c.432]
Таблица 15.7
Значения, используемые при определении коэффициента корреляции (r)
|
х |
у |
ху |
х2 |
у2 |
|
30 |
10 |
300 |
900 |
100 |
Мы подставляем итоговые значения в уравнение:
![]()
![]()
Это говорит нам о том, что наклон у линии регрессии отрицательный (что мы уже, собственно, знали) и что точки [c.433] группируются вокруг нее в ступени от слабой до умеренной (поскольку г изменяется в пределах от +1 до –1 с минимальной связью при r=0).
К сожалению, сам коэффициент r интерпретировать нелегко. Можно, однако, интерпретировать r2 как степень уменьшения ошибки в определении Y на основании значений X, т. е. доля значений Y, которые определяются (или могут быть объяснены) на основе Х. r2 обычно представляют как процентную долю объясненных значений, тогда как (1– r2) – долю необьясненных значений. Так, в нашем примере r значением –0,38 означает, что для тех случаев, которые мы анализируем, разброс независимой переменной составляет (–0,38)2, или около 14%, значений зависимой переменной год обучения.
По причинам, которые находятся за рамками настоящего разговора, определить статистическую значимость г можно только в том случае, если обе – и зависимая и независимая – переменные нормально распределены. Это можно сделать, используя
табл. А.5 в Приложении А, для чего нужны следующие сведения. Во-первых, сам коэффициент г, который, конечно, известен. Во-вторых, аналогично подсчету
χ2 количество степеней свободы линии регрессии. Поскольку прямую определяют любые две точки (в нашем случае пресечение ![]() и
и ![]() – первая точка, и пересечение с осью Y – вторая), все другие точки, обозначающие данные, могут располагаться произвольно, так что df всегда будет равно (N–2), где N – количество случаев или признаков. Таким образом, для того чтобы воспользоваться таблицей, нужно определить примерное количество степеней свободы (в нашем примере N–2 = 25–2 = 23) и желательный уровень значимости (например, 0,05) так же, как мы делали для нахождения χ2, определить пороговое значение r, необходимое для достижения данного уровня значимости, и все подсчитать. (В нашем примере это значит, что мы интерполируем значения в таблице между df=20 и df=25. Для df=23 это будут следующие значения: 0,3379; 0,3976; 0,5069; 0,6194 соответственно.) Таким образом, r=–0,38 статистически значим на уровне 0,10 (он превышает 0,3379), но не на уровне 0,05 (он не превышает 0,3976). Интерпретация этого результата та же, что и в других случаях измерения статистической значимости.
[c.436]
– первая точка, и пересечение с осью Y – вторая), все другие точки, обозначающие данные, могут располагаться произвольно, так что df всегда будет равно (N–2), где N – количество случаев или признаков. Таким образом, для того чтобы воспользоваться таблицей, нужно определить примерное количество степеней свободы (в нашем примере N–2 = 25–2 = 23) и желательный уровень значимости (например, 0,05) так же, как мы делали для нахождения χ2, определить пороговое значение r, необходимое для достижения данного уровня значимости, и все подсчитать. (В нашем примере это значит, что мы интерполируем значения в таблице между df=20 и df=25. Для df=23 это будут следующие значения: 0,3379; 0,3976; 0,5069; 0,6194 соответственно.) Таким образом, r=–0,38 статистически значим на уровне 0,10 (он превышает 0,3379), но не на уровне 0,05 (он не превышает 0,3976). Интерпретация этого результата та же, что и в других случаях измерения статистической значимости.
[c.436]
В этой главе мы познакомили вас с наиболее распространенными статистическими процедурами, которые используются при изучении взаимосвязей между двумя переменными. Как и в гл. 14, мы выяснили, что для разных уровней измерения анализируемых данных подходят разные способы вычисления связи и статистической значимости. Вместе с методами, представленными ранее, рассмотренные коэффициенты снабдят исследователя некоторыми очень полезными основополагающими способами получения научных результатов. В следующей главе мы обратимся к более сложным статистическим методикам, которые обогатят наши возможности анализа и понимание того, что мы изучаем. [c.437]
Дополнительная литература
Библиографию по статистике см. к гл. 16.
1
Об определении этого понятия см.: Freeman L.C. Elementary Applied Statistics: For Students in Behavioral Science – N.Y.: Wiley, 1965.
