 |
 |
|
|
|
|
ПОЛИТОЛОГИЯ: МЕТОДЫ ИССЛЕДОВАНИЯ |
|
|
|
|
|
|
|
|
ПОЛИТОЛОГИЯ: МЕТОДЫ ИССЛЕДОВАНИЯ |
|
НАЗАД Мангейм Дж., Рич Р.К. Политология. Методы исследования ВПЕРЕД
Красным шрифтом в квадратных скобках обозначается конец текста на соответствующей странице печатного оригинала данного издания
ОБРАБОТКА ДАННЫХ
12. ПОДГОТОВКА И ОБРАБОТКА ДАННЫХ
Мы достигли той стадии исследовательского процесса, когда в нашем распоряжении уже имеется массив данных и предстоит выбрать наиболее доступный и эффективный способ его обработки. Именно на этой стадии мы начинаем окончательное оформление результатов наших усилий в виде схем, графиков, статистических выкладок и других элементов, составляющих отчет о проделанной научной работе; эту часть нашего исследования мы представляем для всеобщего обозрения и прочтения. Однако остается еще один гораздо менее заметный комплекс операций, которых нельзя избежать, если мы хотим извлечь из наших данных наиболее полную информацию. Имеется в виду подготовка и обработка данных, чему будет посвящена настоящая глава. Как исследователь приписывает цифровые значения той информации, которую он или она собрали, чтобы можно было бы ее основательно проанализировать? Как можно использовать эти цифры, чтобы осмысленно связаться с компьютером, без которого обрабатываемые нами массовые данные зачастую становятся неуправляемыми? Что в этом случае компьютер может сказать нам о наших данных? Как мы должны спрашивать его? Эти и другие имеющие отношение к делу вопросы должны быть решены прежде, чем мы перейдем к анализу данных и презентации результатов. [c.356]
КОДИРОВАНИЕ: ЧТО ВСЕ ЭТИ ЦИФРЫ ЗНАЧАТ?
Процесс присвоения количественных значений имеющейся у нас информации называется кодированием. Кодирование для измерений значит то же, что алфавит для речи, а именно средство, с помощью которого информации придается форма связного и продолжительного сообщения. Так же как каждая буква или комбинация букв алфавита представляет определенный звук, каждая цифра или комбинация цифр кода представляет определенную характеристику или состояние исследуемого объекта. И так же, как буквы позволяют тем, кто знает алфавит, оперировать сложными мыслями, цифры позволяют тем, кто [c.356] знает код, оперировать сложными понятиями в более сокращенной форме. Кроме того, цифровая кодировка дает возможность исследователю пойти еще дальше, поскольку кодированная информация, особенно кодированная в цифровой форме, позволяет применить математические методы, и тогда полученные данные могут выявить то, что без обращения к цифровой интерпретации могло остаться скрытым. Другими словами, кодирование открывает путь к более глубокому исследованию, чем это могло бы быть в любом другом случае.Цифровые коды в исследовательской работе очень похожи на азбуку Морзе в телеграфии, с которой вы, вероятно, знакомы. В азбуке Морзе определенные комбинации точек и тире заменяют буквы алфавита. Сами точки и тире преобразуются в длинные и короткие звуки, которые могут быть переданы по радио от соответственно оборудованной передающей станции к соответственно оборудованному приемнику. Звуки затем преобразуются в буквы, и передача сообщения, таким образом, завершена. На рис. 12.1 этот процесс изображен в форме диаграммы.
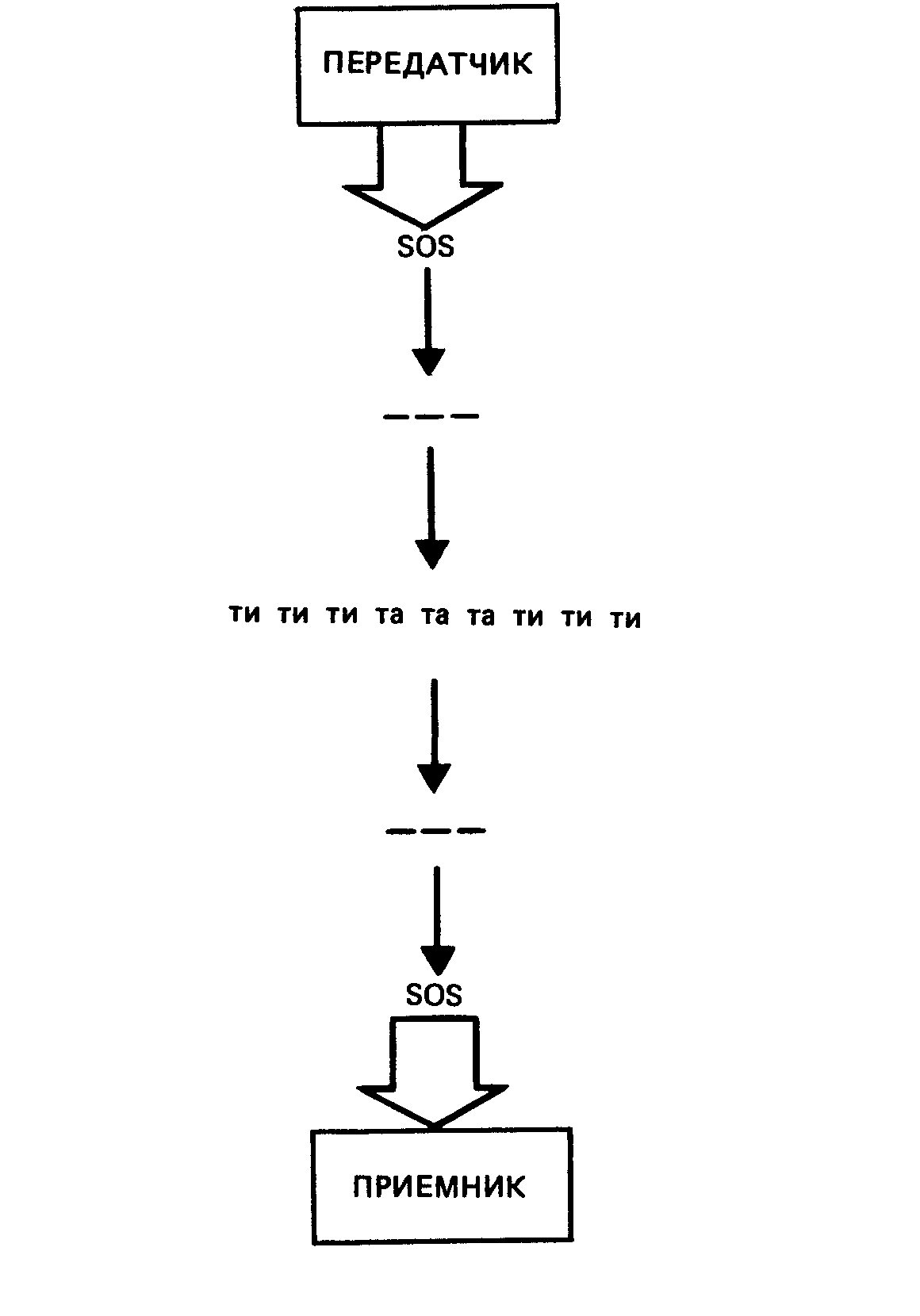
Рис. 12.1. Кодирование в телеграфии
Точно также в научном исследовании каждая цифра кода означает определенную градацию данной переменной. Например, если мы измеряем уровень образования членов определенной группы, в которой каждый опрашиваемый может иметь незаконченную высшую школу, законченную высшую школу и законченное высшее образование колледжа, мы можем представить эти три уровня градаций цифрами 1, 2, 3. Или же, если мы хотим учесть число лет обучения, цифровой код должен отражать это число (например, цифра 7 будет значить семь лет обучения). Обе системы кодирования позволяют довольно точно подытожить результаты исследования, хотя принципы, кодирования разнятся. Ну и, поскольку мы имеем комплекс закодированных в той или иной форме данных, можно обрабатывать и анализировать их в соответствии с нашими желаниями, прежде чем преобразовывать их обратно в словесную форму при подготовке отчета о нашей нагнои деятельности. Этот процесс перевода информации из словесной формы в цифровую и обратно в обобщенной форме показан на рис. 12.2.
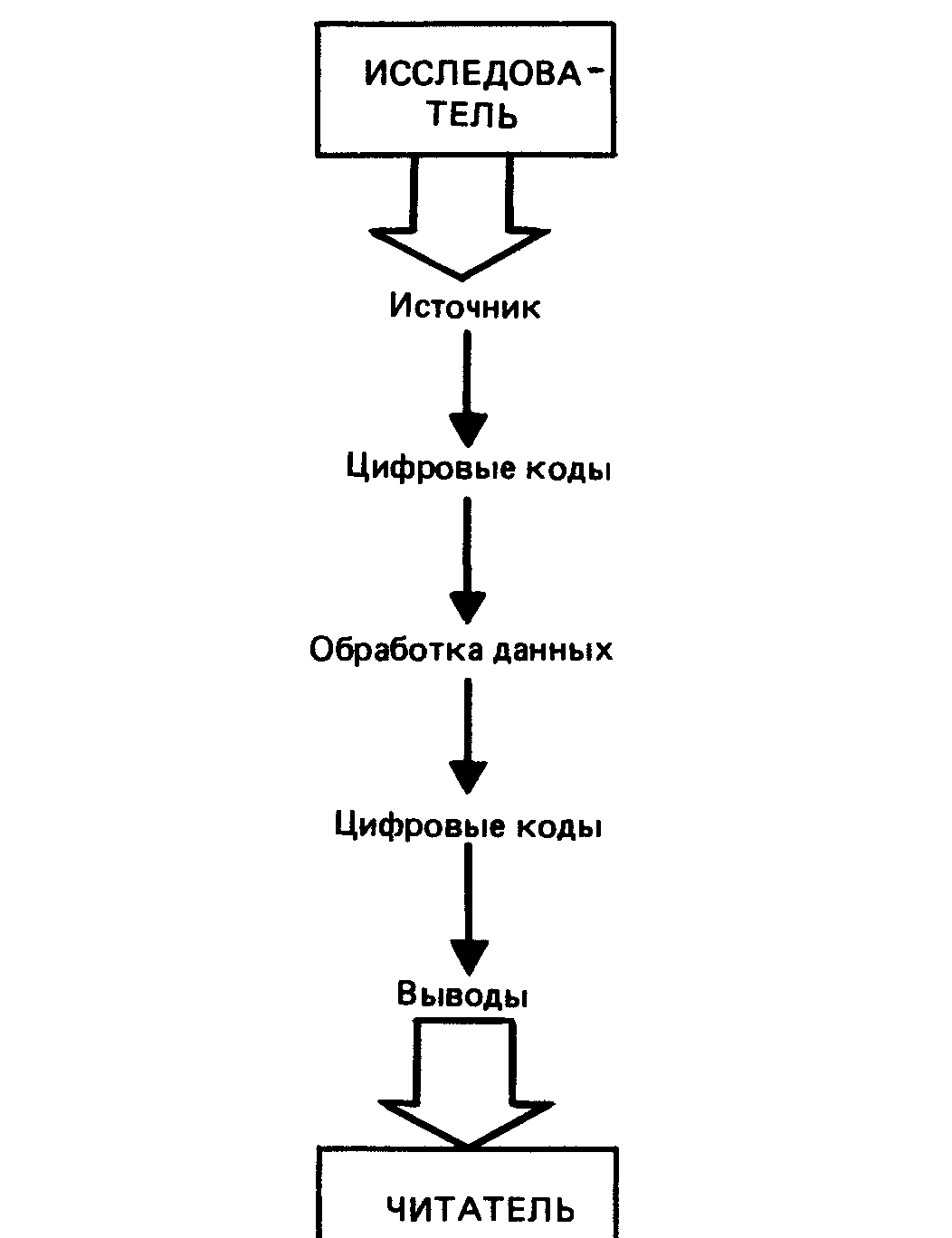
Рис. 12.2. Кодирование в исследовании
Самое главное, что необходимо помнить при разработке кодирования данных, – это то, что принцип [c.357] кодирования должен всегда определяться характером измерения исследуемой переменной. Так, переменные, измеряемые номинальными шкалами, должны иметь номинальные коды, переменные, измеряемые шкалами порядков, – порядковые, и переменные, измеряемые интервальными шкалами, – интервальные. Внешне все эти цифры могут казаться [c.358] одними и теми же, однако их значения в каждом случае существенно отличны от других. Анализ или оперирован данными, преобразованными из словесной формы в цифровую, чреваты непреодолимым искушением применить м годы, которые просто невозможны в данном случае в си особенностей измерения переменной (более подробно мы рассмотрим эту проблему в следующих главах). Такое искушение нужно преодолеть, если мы хотим извлечь пользу своего исследования. [c.359]
Механизм закодирования (или раскодирования) данных действительно очень прост. Мы начнем с определения типа каждой переменной нашего исследования с точки зрения шкалы ее измерения. Если это номинальная переменная, в которой нам нужно распределить цифры кода между взаимоисключающими категориями, невзирая на порядок их расположения, то мы делаем это так, как нам удобно. Возьмем довольно типичный пример. Если члены исследуемой группы подразделяются по вероисповеданию на протестантов, католиков и иудеев, то распределить коды между этими категориями можно согласно любой из нижеследующих схем:
|
|
1 Протестанты |
1 Католики |
1 Иудеи |
43 Протестанты |
|
В каждом случае отдельная цифровая градация используется для обозначения градации или категории переменной. Поскольку вероисповедание есть номинальная характеристика, порядок расположения и размерность кода не имеют никакого значения. Мы можем при кодировании использовать одно-, трех- и даже десятизначные цифры, если нам этого захочется. Конечно, лучше давать наиболее простые и удобные коды, и обычно выбирают простые цифры с наименьшим количеством знаков, но вообще это зависит от нашей приверженности к экономии, а не от каких-либо математических требований.
Можно также использовать более сложную схему номинального кодирования для более полного отражения информации. Например, мы хотим в нашем исследовании более подробно представить информацию о лицах протестантского и иудейского вероисповедания. Тогда мы можем использовать систему двузначных кодов, которая строится на предыдущей классификации. В качестве первой цифры выбираем ту же, что и ранее (например, 1 – протестанты, 2 – католики, 3 – иудеи). Вторая будет обозначать новую информацию. Взгляните на следующую схему:
|
|
10 Протестанты |
20 Католики |
|
[c.360]
Здесь наши коды отражают (в первой колонке) приблизительную разницу между категориями и в то же время (вторая колонка) дают возможность уточнения. В результате мы имеем более полную запись характеристик исследуемых лиц, которая вместе с тем сохраняет следы менее точной (но зачастую более удобной с точки зрения анализа) системы записи, с которой мы начали.
Если бы нам нужно было перечислить все градации протестантского вероисповедания, то возможности кода в диапазоне “10” (от 10 до 19) вскоре были бы исчерпаны и нам пришлось бы изменить схему записи. Любой из нижепредложенных вариантов может легко решить эту проблему, хотя выбор того или иного пути может варьироваться в зависимости от задач исследовательского анализа или навыков компьютерного программирования.

В первом случае мы просто увеличили количество двузначных кодов (комплектов десятичных кодов), приписанных протестантам, тогда как во втором – упорядочили их. И опять если переменная, по сути, является номинальной, то ни конкретная цифра, ни количество знаков кода не имеют никакого значения. До тех пор пока наша система кодировки является оптимально экономной, а градации переменной – взаимоисключающими, любая цифра удовлетворительна. [c.361]
Когда мы кодируем порядковые переменные, наши возможности уже несколько ограничены. Поскольку порядковое измерение не предполагает равных или просто известных нам интервалов, мы остаемся, вольны в выборе цифр любой величины. Но поскольку порядковое измерение требует сохранения в наших кодах относительного ранжирования градаций (позиций), мы должны заботиться о том, чтобы наши цифры были по меньшей мере определенным образом расположены. Так, для переменной уровень политического развития или любой другой переменной, содержащей разницу в уровне, степени или сходстве градаций, любая из предложенных ниже систем кодировки может быть одинаково верной (и одинаково значимой).
|
|
1 Самый низкий |
|
1 Самый низкий |
1 |
Самый низкий |
Каждая из них сохраняет порядок, заданный самой переменной. И ни одна не является более точной, чем остальные, поскольку точность здесь – функция не самих цифр, а стоящего за ними порядкового измерения. Как и ранее, наша приверженность к экономии может подтолкнуть нас к выбору первой из трех предложенных схем, однако если не принимать этого во внимание, то наш выбор строго случаен.
Напротив, ни одна из следующих схем не является подходящей:
|
|
1 Самый низкий |
1 Высший |
|
Если относительная величина или расположение цифровых кодов (а следовательно, и направление их изменения) не имеют значения для номинальных измерений, то в случае работы с порядковыми данными они очень важны. В первом из вышеприведенных примеров смещен порядок кодов, во втором он изменен на обратный. В результате ни одна из систем кодировки не сохраняет в достаточной мере относительного расположения и величины градаций самой переменной. Таким образом, коды неверно передают сведения. Они либо лишают нас возможности выстроить наши данные по порядку, либо вводят в заблуждение относительно причин [c.362] той систематизации, которую мы пытаемся выработать. Короче говоря, подобных ошибок нужно избегать при работе с порядковыми данными.
Разработка кодов для интервальных измерений, с одной стороны, – наиболее трудоемкий процесс, однако с другой – он может оказаться наилегчайшим. Здесь цифры имеют гораздо более точное значение, и наши возможности в кодировании существенно ограничены. Доллар – это доллар, год – это год, а разница между 47 и 43% такова же, как и между 73 и 69%. В интервальном измерении не только величины являются взаимоисключающими и определяющими порядок расположения, но и интервал между двумя соседними значениями одинаков и неизменен. Кодирование интервальных данных должно сохранять эти характеристики.
На первый взгляд это может показаться невыполнимой задачей. Для того чтобы закодировать интервальную переменную, необходимо найти такую систему кодов, где каждый исключает другие, каждый соответствует определенной величине переменной, каждый отстоит на равное количество единиц измерения от ближайшего соседа и дистанция эта между двумя соседними величинами известна. В действительности, однако, нахождение таких цифр, в общем-то, простая задача, поскольку в отличие от большинства номинальных или порядковых шкал, когда исследователь, по сути дела, вынужден выискивать цифровые эквиваленты для своих сведений, многие интервальные коды заданы изначально. Иными словами, интервальные коды гораздо чаще, чем на более низких уровнях измерения, следуют непосредственно из операционных характеристик самой переменной. Если определить личный доход как количество долларов, которое он или она зарабатывает за определенное время, то каждое конкретное количество заработанных долларов определяет не только какую-либо градацию переменной дохода, но и код для этой градации. Если градации номинальных и порядковых переменных в основе своей являются вербальными (как, например, протестант и католик, высокий и низкий уровни развития) и должны быть заменены цифровыми эквивалентами, то градации интервальных переменных изначально имеют цифровую форму (доллары дохода при исчислении стажа работы в административном [c.363] учреждении) и не требуют специального перевода. Результатом является то, что при кодировании интервальных данных основное внимание уделяется не созданию имеющих смысл кодов, а опознаванию и сохранению их.
Как отмечалось в гл. 3, иногда могут возникнуть такие ситуации, когда исследователь, желая повысить возможности обработки и информационную отдачу своих данных, захочет свести интервальные данные к порядковым категориям. Например, для нас гораздо проще и значимее может оказаться анализ респондентов по общему уровню их доходов, чем учет каждого доллара разницы. В таких случаях в первоначальной кодировке данных можно сохранить их интервальный характер, а затем полученные категории преобразовать согласно нуждам исследователя (например, мы записываем действительное количество долларов, заработанных респондентами, а затем группируем их в более крупные категории) или же можно действовать по методу, когда данные сразу, по мере поступления записываются в сгруппированном виде так, как будто мы классифицируем респондентов по большим категориям дохода и не фиксируем точный размер их заработка. Каждый метод имеет свои достоинства и свои недостатки, которые должны учитываться в каждом конкретном случае. Какой бы метод ни был взят, исследователь должен быть уверен, что выбранная схема кодирования отвечает требованиям измерения конкретного признака.
Становится очевидным, что процесс приписывания определенных кодов данным неотделим от процесса операционализации переменных. Безусловно, коды – это ничто иное, как цифровое выражение наших операциональных определений. Поэтому обсуждение проблемы кодирования было бы более уместно в начале книги. Все вопросы, связанные с тем, какие коды дать градациям переменных, должны быть решены на ранних стадиях исследовательского процесса. Все это неотъемлемая часть верного планирования исследования. Однако истинная ценность кодов становится понятной позже, поскольку именно на стадии анализа данных коды начинают играть ту роль, которую они призваны сыграть во всем проекте исследования. Именно тогда коды дают возможность перейти от обзора к обработке данных, а затем от обработки – к интерпретации. Для того чтобы понять, как происходит этот переход, давайте рассмотрим некоторые аспекты техники кодирования. [c.364]
КНИГА КОДОВ И КОДИРОВАЛЬНЫЙ БЛАНК
Первое, что нам следует рассмотреть, – это книга кодов. Книга кодов – это перечень всех переменных, встречающихся в исследовании, всех значений, которые могут принимать переменные, и всех приписанных им цифровых значений.Представьте, например, что 1 июля 1995 г. правительства Ирана, Никарагуа и Вьетнама заключили соглашения с некоторыми рекламными агентствами с целью улучшения своего имиджа в американской прессе и что мы хотим провести исследование, для того чтобы определить, каково воздействие этих усилий на содержание новостей и редакционных статей. В таком исследовании нам можно сравнить период, непосредственно предшествующий, и период, непосредственно следующий за исходной датой, с тем чтобы установить, что произошло после заключения контрактов: 1) количество репортажей о каждой) стране значительно возросло или значительно упало, 2) отношение к этим странам в прессе более предпочтительно или менее предпочтительно, чем в предыдущий период. Необходимо также учитывать такие дополнительные факторы, как регулярные сезонные перемены в репортажах, например большее внимание прессы к некоторым странам в период туристского сезона, или увеличение потока достойных внимания прессы событий во время обострения политической ситуации или в результате стихийных бедствий; однако для большей наглядности мы не будем обращать внимание на эти факторы.
Для того чтобы оценить эффект усилий по улучшению имиджа, мы можем обратиться к любому количеству репортажей новостей или проанализировать лишь перечень, который может быть в форме как заголовков, так и кратких резюме различных статей и содержит, по сути дела, значительную долю информации; можно также использовать его лишь для обозначения самих статей. Для наглядности давайте воспользуемся перечнем (который в нашем случае содержит заголовки и полные библиографические ссылки) в “Reader's guide to Periodical Literature”, в котором публикуется содержание большого количества популярных журналов; выберем гуда заголовки “Иран”, “Никарагуа”, “Вьетнам”. Нашей зависимой переменной будет деятельность профессиональных рекламных агентств, точнее, ее отсутствие (до l июля 1995 г.) или присутствие (после этой даты). [c.365]
Следуя двум отмеченным принципам, мы будем иметь два комплекса зависимых переменных. В первом будет учитываться количество статей, в нем будет отмечаться ежемесячное количество их в период до и после тестирования и соотношение (на основании заголовка или содержания) статей, относящихся к политической, экономической или социальной системам каждой страны. В дальнейшем мы будем обозначать эти статьи как затрагивающие внутренние или внешние проблемы. Второй комплекс зависимых переменных будет учитывать качество репортажей на основании суждений о том, насколько положительно или отрицательно (опять же на основании заголовков) оцениваются в них названные страны. И, наконец, в любом исследовании такого рода необходимо иметь специальные коды для обозначения каждой отдельной статьи, страны, к которой она относится, даты публикации, объема статьи, типа издания, в котором она появилась.
В упрощенном виде макет кодировки для этого гипотетического исследования представлен в табл. 12.1. Как видите, макет кодировки суммирует переменные, используемые в исследовании, и приданные им значения. Это, по сути дела, немного больше, чем просто формальная классификация, с которой начинается любое исследование. Здесь эта классификация представлена во всех деталях, включая инструкции к интерпретации, и структура ее построена не в соответствии с нашими гипотезами, а с тем, чтобы облегчить сбор информации. Книга кодов обеспечивает постепенное продвижение к тому, что мы пытаемся выяснить, а также описание этого искомого, когда мы его нашли.
Эта “Книга кодов” идентифицирует компьютерные колонки, в которых будут храниться данные, а также предоставляет описания информации, которая должна быть найдена в определенном месте. Она также сообщает, какие коды были использованы для представления данных, не являющихся числовыми. Например, кодовая таблица, представленная в табл. 12.1, показывает, что номер 1, обнаруженный в компьютерной колонке 16, означает тип журнала, в котором была найдена искомая статья, а именно – еженедельник (как, например, “Time” или “Newsweek”). Такая организация информации помогает исследователю записывать данные правильно и аккуратно интерпретировать результаты анализа, после того как он закончен. А [c.366] тем, кто может использовать эти данные впоследствии, это также дает возможность увидеть, как организованы данные, и в свою очередь интерпретировать результаты анализа, не опираясь на уже существующее мнение.
Таблица 12.1.
Макет кодировки для исследования “Информационные агентства о некоторых странах”
|
Колонка |
Переменная |
Значение переменной |
Код |
|
1 - 4 |
Статья и номер кодирования |
|
- |
|
5 |
Государства |
Иран |
1 |
|
6 - 7 |
Месяц публикации |
Июль 1995 |
01 |
|
8 |
Отношение к политической системе в заголовке статьи (включая любое упоминание о политических деятелях, правительствах, политических событиях, оппозиционных партиях, политике и т.д.) |
Не относится |
0 |
|
9 |
Отношение к экономической системе в заголовке статьи (включая любое упоминание о промышленности, экономике, денежном курсе, рабочей силе, продукции, экономических возможностях, рынке, торговле и т.д.) |
Не относится |
0 |
|
10 |
Отношение к социальной системе в заголовке статьи (включая любое упоминание о культурных, религиозных и социальных институтах, событиях или деятелях и т.д.) |
Не относится |
0 |
|
11 |
Посвящена внутренним или внешним проблемам |
Заголовок статьи относится исключительно к внутренним объектам, действиям или событиям |
|
|
12 |
Положительное или отрицательное отношение |
Заголовок статьи касается исключительно прогресса, достижений, ресурсов, активов, мощи страны |
|
|
13 - 15 |
Количество страниц в статье |
|
- |
|
16 |
Тип журнала, опубликовавшего статью |
Еженедельник новостей (включая только “Time”, “Newsweek”, “U.S. News and World Report”) |
|
Разработка книги кодов облегчает быстрый переход к следующей стадии подготовки данных – созданию кодировального бланка. Кодировальный бланк – это лист записи данных в соответствии с книгой кодов и в форме, облегчающей компьютерную обработку собранной информации. Обзорная анкета и форма записи для структурированной информации, описанные в предыдущих главах, являются, например, вариантами кодировального листа, так же как и представленная на рис. 12.3 запись сведений в нашем исследовании репортажей о различных странах в американской прессе. [c.368]
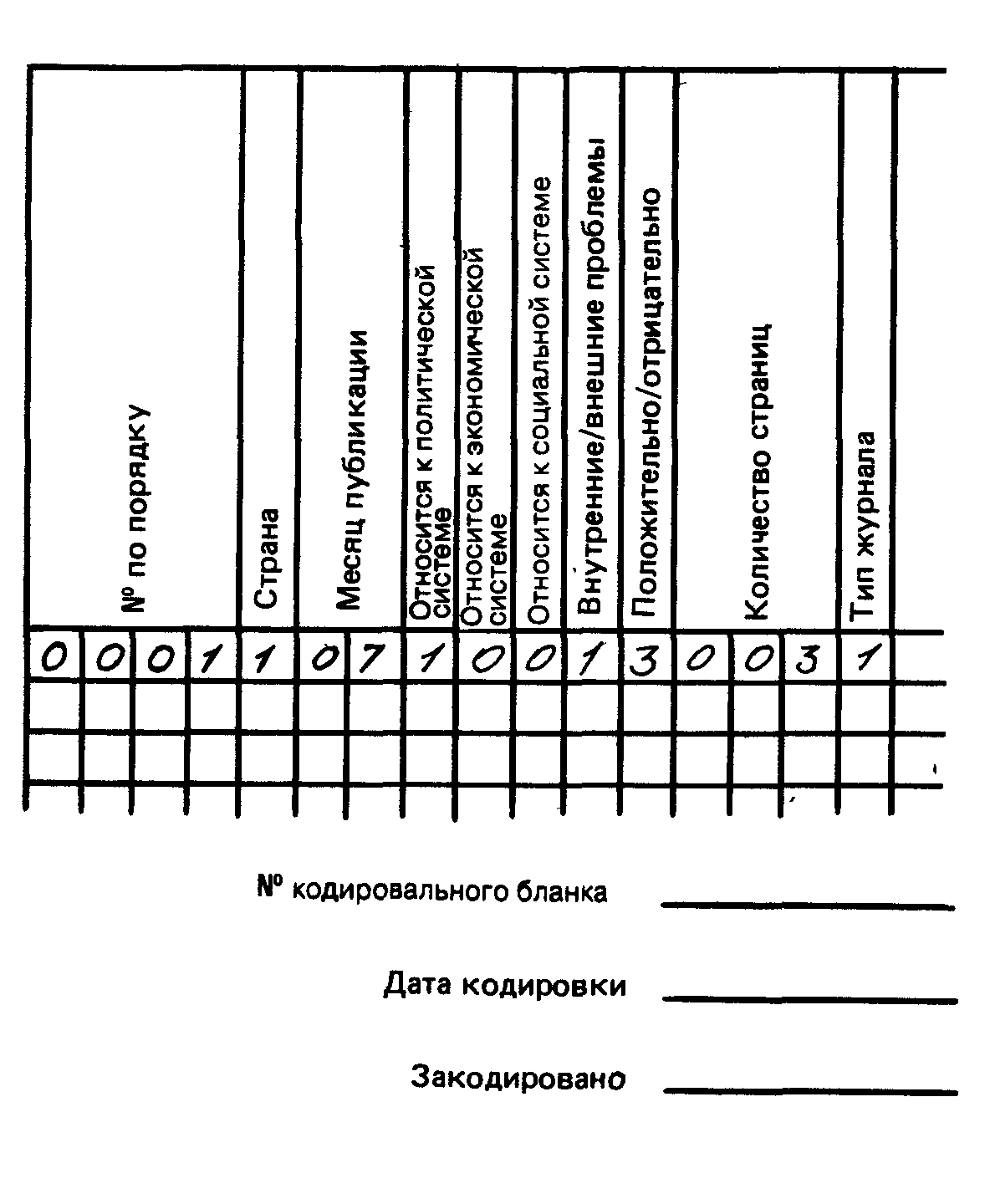
Рис. 12.3. Кодировальный бланк для исследования “Пресса США о некоторых странах”
На рис. 12.3 в колонки занесены признаки книги кодов. На каждую цифру кода отведена специальная колонка; так, двухпорядковый код (такой, как у переменной месяц публикации) требует двух колонок в копировальном листе. Точно так же каждый ряд представляет отдельный случай и каждая цифра обозначает значение переменной в каждом конкретном случае. Так, мы видим, что под номером 0001 описана статья об Иране, которая появилась в еженедельнике новостей в январе 1996 г., посвящена исключительно политической системе и не содержит упоминаний об определенных затруднениях во внутренней ситуации. Этим характеристикам может отвечать, например, статья [c.369] из “Тайм”, озаглавленная “Иран в хаосе: руководители не в состоянии остановить казни, стабильность под угрозой”. И таким же образом могут быть записаны относительные характеристики заголовка любой статьи, которую мы встретим; при этом каждая статья (каждый отдельный случай) будет занимать один ряд или строку. И если мы изучим, или закодируем, 821 случай, то все данные займут всего 821 ряд. Данные разных случаев (статей), но относящиеся к одному и тому же признаку, будут записаны в одних и тех же колонках на кодировальном бланке. И, наконец, все кодировальные бланки следует пронумеровать (чтобы быть уверенным, что ни один из них не потерялся), датировать (даты часто бывают, полезны, например, если мы вынуждены изменить формулировку или добавить переменную в книгу кодов и приходится перекодировать или добавлять коды к предыдущему материалу) и подписать полным именем или инициалами кодировщика (это основа для измерения надежности интеркодирования, описанной в гл. 9). Если для каждого случая требуется больше одного кодировального бланка, например когда количество переменных, которые нужно измерить, достаточно велико, все бланки, относящиеся к одной группе случаев, следует скрепить и пронумеровать однотипно. Это сведет к минимуму шансы перепутать их при обработке. Имеет также смысл выносить порядковый номер каждого случая на отдельный копировальный бланк, используемый для него. [c.370]
Когда кодировка данных закончена, мы обращаемся к их обработке, с тем чтобы прийти к каким-либо выводам. Понятно, что в работе с большим количество случаев и переменных путаница может быть абсолютно непреодолимой. Если мы хотим преодолеть эту трудность и добиться максимальной простоты, точности и емкости анализа, нужно положиться на компьютер. Конечно, компьютер – очень сложная система, но ее основные принципы несложно понять.
Компьютеры состоят из комплектов выключателей (кнопок), которые используются для набора информации посредством простых кодов. Можно проиллюстрировать это, пользуясь аналогией с выключателями света в вашем
[c.370] доме. Выключатель может выполнять только два типа операций. Он либо включен, либо выключен, посредством постановки в ту или иную позицию выключатель (и свет) могут быть использованы для передачи информации. Если, например, вы хотите, чтобы в канун Дня всех святых ваши дети навестили вас, вы информируете об этом, включая свет у дверей вашего дома. Если вы не хотите, чтобы вас беспокоили, вы не станете включать свет. По сути дела, вы передаете сообщение посредством замыкания и размыкания электрической цепи. Точно так же, сочетая комплекты выключателей и лампочек и используя двоичную систему исчисления (описанием которой мы сейчас не станем заниматься), вы можете составлять все более и более сложные информационные сообщения. Построение такой системы кодов по типу “да – нет” и использование ее для обмена информацией можно представить себе как программирование ваших действий с выключателями света. Собственно говоря, так компьютер и работает, конечно, в гораздо большем и более сложном масштабе. Обычный компьютер состоит из многих тысяч маленьких выключателей, запрограммированных на сбор и обработку информации точно таким путем.Некоторые виды анализа – особенно такие, в которых задействованы очень большие объемы данных или очень сложные процедуры обработки, – производятся на компьютерах типа “мэйнфрейм”, но большинство политологических исследований могут быть сделаны и на достаточно быстрых персональных компьютерах с большой памятью. Для “общения” с компьютером мы используем различные средства – от пишущей машинки консоли до оптической “мышки” и светочувствительного пера. Информация, вводимая в компьютер с помощью клавиатуры (или какими-то другими средствами), конвертируется в электронные коды, которые хранятся в виде, предварительно оговоренном. Каждой строке информации соответствует строка в кодировочной таблице. Таким образом, продолжая разговор о нашем примере, чтобы ввести коды 821 статей о трех запрашиваемых странах, мы должны были напечатать их в 821 строке данных на клавиатуре.
Некоторые программы пригодны для проведения статистического анализа на персональных компьютерах. Они различаются по форме и возможностям. Одни – особенно
[c.371] разработанные для компьютеров “Apple” или IBM совместимых систем, использующих программное обеспечение типа “Windows”, – ориентированы на визуальные (графические) команды. Другие – IBM совместимые системы, использующие операционную систему MS-DOS, – ориентированы на текстовые команды. Разнообразие аппаратного и программного обеспечения слишком велико, чтобы подробно рассматривать его на этих страницах. Однако что касается ввода данных, то в наиболее современных программах используется обычно формат, называющийся “электронные таблицы”*.При использовании электронных таблиц сначала необходимо пометить и определить значение колонок для ввода данных, установив параметры (число колонок, необходимых для каждой переменной, тип и определяющие метки). Затем производят ввод данных построчно, причем в каждой строке должен быть представлен отдельный случай или наблюдение. Соответствующие колонки заполняются цифрами или буквами. Все это выглядит достаточно знакомо, ибо процедура совершенно совпадает с созданием программного бланка (coding sheet), которое мы описали выше.
Когда данные введены в компьютер, их нужно обрабатывать. Это значит, что мы должны “проинструктировать” компьютер, каковы наши требования к их обработке. Какие случаи нам нужно проанализировать? Какие подсчеты должны быть выполнены? В какой форме мы хотим получить результаты?
Полезно уметь писать компьютерные программы, но нет никакой необходимости создавать свою собственную программу, для того чтобы проанализировать большинство данных, привлекаемых для политологического исследования. Пригодное для этого программное обеспечение включает в себя очень сложные и хитроумные программы, выполняющие разнообразные статистические, аналитические, текстовые и другие операции. Но даже если программы сами по себе сложны, то использовать их [c.372] очень легко. В каждой имеется своеобразная “поваренная книга” для обработки данных. Эта “книга”, или учебник, содержит пошаговые инструкции по использованию программы и выполнению определенных задач. В сущности, компьютер задает нам разные вопросы, посылая на экран сообщения типа: “Хотите ли вы, чтобы я вывел на экран эти данные в виде таблицы?” или “Вы хотите посчитать среднее квадратическое отклонение для этих случаев?” Следуя инструкциям, мы отвечаем “да” или “нет” и указываем на специфические процедуры, которые мы хотим проделать. Форма и суть этих инструкций меняются в зависимости от пакета, но в целом функции их одинаковы. Таким образом, на самом деле нет необходимости создавать программы, поскольку есть возможность пользоваться уже имеющимися в компьютере.
В заключение хочется сделать еще три замечания. Во-первых, довольно распространено явление, когда люди, не имеющие прежнего опыта работы с компьютером, теряются и слегка побаиваются его. Такие чувства понятны, однако нельзя позволять им становиться препятствием в обучении. При наличии всех закрытых программ, руководств и консультационных служб, которые сейчас существуют, использование компьютера значительно облегчается по сравнению с прежними временами. Когда, наконец, вы преодолеете свои сомнения, то, возможно, обнаружите, что попались компьютеру “на крючок” и получите огромное удовольствие от общения с ним.
Во-вторых, не стесняйтесь ошибаться. Внимательный ввод данных и считывание предотвратят многие ошибки, И, как в любой новой сфере, вы вскоре найдете пути улучшения работы. Это – обычное дело. Если подумать, ошибки и их исправление – один из наиболее важных моментов обучения. Следите за своими ошибками там, где это возможно, не отказывайтесь от помощи там, где это необходимо, и не прекращайте своих попыток.
И наконец, не увлекайтесь. Компьютеры по природе своей бестолковы; они обрабатывают информацию, они точно следуют командам, но они не думают. Используя пакеты программ, которые мы здесь описали, вы можете с легкостью заставить компьютер выполнять сложнейшие статистические расчеты, какие только можно вообразить, данных такого низкого уровня, что результаты, несмотря [c.373] на впечатляющую внешнюю форму, будут бессмысленны. Соответственно, очень важно, чтобы вы заранее продумывали и понимали статистические и аналитические процедуры, которые предстоит осуществить компьютеру, и отбирали только те, которые соответствуют вашим данным. Эти процедуры будут предметом обсуждения нескольких следующих глав. [c.374]
Дополнительная литература
Более детально процедуры кодирования рассмотрены в кн.: Janda К. Data Processing: Applications to Political Research, 2nd.ed. – Evanstone (Ill.): Northwestern University Press, 1969.
Полезные примеры использования книги кодов см. в: Janowitz М. The Community Press in an Urban Setting: The Social Elements of Urbanism. - 2nd ed.– Chicago: University of Chicago Press, 1967; Leuthhold D.A. Electioneering in a Democracy. Campaigns for Congress. – N.Y.: Wiley, 1968.
*
Исключение составляют специализированные программы, например, предназначенные для компьютерной организации опросов или для автоматизированного контент-анализа. Поскольку эти программы сложны для новичков, они не обсуждаются специально.
